
What is semi-supervised machine learning?
لقد أثبت التعلم الآلي أنه فعال للغاية في تصنيف الصور والبيانات غير المنظمة الأخرى، وهي مهمة يصعب التعامل معها باستخدام البرامج التقليدية القائمة على القواعد. ولكن قبل أن تتمكن نماذج التعلم الآلي من أداء مهام التصنيف، يجب تدريبهم على الكثير من الأمثلة المشروحة. التعليقات التوضيحية على البيانات هي عملية بطيئة ويدوية تتطلب من البشر مراجعة أمثلة التدريب واحدًا تلو الآخر ومنحهم التسمية الصحيحة.
في الواقع، يعد التعليق التوضيحي للبيانات جزءًا حيويًا من التعلم الآلي لدرجة أن الشعبية المتزايدة للتكنولوجيا أدت إلى ظهور سوق ضخم للبيانات المصنفة. من Amazon's Mechanical Turk إلى الشركات الناشئة مثل LabelBox و ScaleAI و Samasource، هناك العشرات من المنصات والشركات التي تتمثل مهمتها في إضافة تعليقات توضيحية إلى البيانات لتدريب أنظمة التعلم الآلي.
لحسن الحظ، بالنسبة لبعض مهام التصنيف، لا تحتاج إلى تصنيف جميع أمثلة التدريب الخاصة بك. بدلاً من ذلك، يمكنك استخدام التعلم شبه الخاضع للإشراف، وهو أسلوب تعلم آلي يمكنه أتمتة عملية تصنيف البيانات بقليل من المساعدة.
في الواقع، يعد التعليق التوضيحي للبيانات جزءًا حيويًا من التعلم الآلي لدرجة أن الشعبية المتزايدة للتكنولوجيا أدت إلى ظهور سوق ضخم للبيانات المصنفة. من Amazon's Mechanical Turk إلى الشركات الناشئة مثل LabelBox و ScaleAI و Samasource، هناك العشرات من المنصات والشركات التي تتمثل مهمتها في إضافة تعليقات توضيحية إلى البيانات لتدريب أنظمة التعلم الآلي.
لحسن الحظ، بالنسبة لبعض مهام التصنيف، لا تحتاج إلى تصنيف جميع أمثلة التدريب الخاصة بك. بدلاً من ذلك، يمكنك استخدام التعلم شبه الخاضع للإشراف، وهو أسلوب تعلم آلي يمكنه أتمتة عملية تصنيف البيانات بقليل من المساعدة.
التعلم الآلي الخاضع للإشراف مقابل التعلم الآلي شبه الخاضع للإشراف
تحتاج فقط إلى أمثلة معنونة لمهام التعلم الآلي الخاضعة للإشراف، حيث يجب عليك تحديد الحقيقة الأساسية لنموذج الذكاء الاصطناعي الخاص بك أثناء التدريب. تتضمن أمثلة مهام التعلم الخاضعة للإشراف تصنيف الصور، والتعرف على الوجه، والتنبؤ بالمبيعات، والتنبؤ بتضخم العملاء، واكتشاف البريد العشوائي.
من ناحية أخرى، يتعامل التعلم غير الخاضع للإشراف مع المواقف التي لا تعرف فيها الحقيقة الأساسية وتريد استخدام نماذج التعلم الآلي للعثور على الأنماط ذات الصلة. تتضمن أمثلة التعلم غير الخاضع للإشراف تقسيم العملاء واكتشاف الأخطاء في حركة مرور الشبكة وتوصية المحتوى.
يقف التعلم شبه الخاضع للإشراف في مكان ما بين الاثنين. إنه يحل مشاكل التصنيف، مما يعني أنك ستحتاج في النهاية إلى خوارزمية تعلم خاضعة للإشراف للمهمة. ولكن في الوقت نفسه، تريد تدريب النموذج الخاص بك دون تسمية كل مثال تدريبي فردي، حيث ستحصل على المساعدة من تقنيات التعلم الآلي غير الخاضعة للإشراف.
التعلم شبه الخاضع للإشراف مع خوارزميات التجميع والتصنيف
تحتاج فقط إلى أمثلة معنونة لمهام التعلم الآلي الخاضعة للإشراف، حيث يجب عليك تحديد الحقيقة الأساسية لنموذج الذكاء الاصطناعي الخاص بك أثناء التدريب. تتضمن أمثلة مهام التعلم الخاضعة للإشراف تصنيف الصور، والتعرف على الوجه، والتنبؤ بالمبيعات، والتنبؤ بتضخم العملاء، واكتشاف البريد العشوائي.
من ناحية أخرى، يتعامل التعلم غير الخاضع للإشراف مع المواقف التي لا تعرف فيها الحقيقة الأساسية وتريد استخدام نماذج التعلم الآلي للعثور على الأنماط ذات الصلة. تتضمن أمثلة التعلم غير الخاضع للإشراف تقسيم العملاء واكتشاف الأخطاء في حركة مرور الشبكة وتوصية المحتوى.
يقف التعلم شبه الخاضع للإشراف في مكان ما بين الاثنين. إنه يحل مشاكل التصنيف، مما يعني أنك ستحتاج في النهاية إلى خوارزمية تعلم خاضعة للإشراف للمهمة. ولكن في الوقت نفسه، تريد تدريب النموذج الخاص بك دون تسمية كل مثال تدريبي فردي، حيث ستحصل على المساعدة من تقنيات التعلم الآلي غير الخاضعة للإشراف.
التعلم شبه الخاضع للإشراف مع خوارزميات التجميع والتصنيف

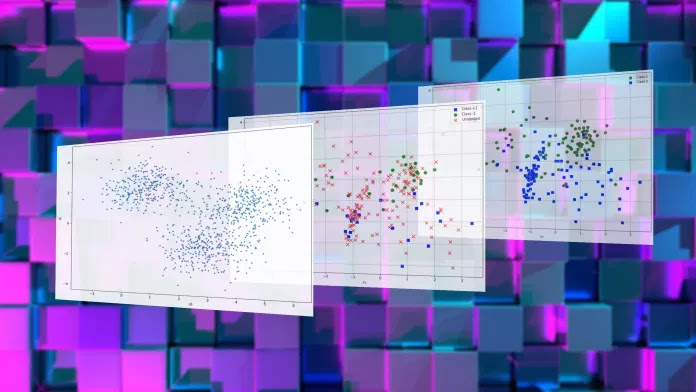
تتمثل إحدى طرق القيام بالتعلم شبه الخاضع للإشراف في الجمع بين خوارزميات التجميع والتصنيف. خوارزميات التجميع هي تقنيات تعلم آلي غير خاضعة للإشراف تجمع البيانات معًا بناءً على أوجه التشابه بينها. سيساعدنا نموذج التجميع في العثور على العينات الأكثر صلة في مجموعة البيانات الخاصة بنا. يمكننا بعد ذلك تصنيفها واستخدامها لتدريب نموذج التعلم الآلي الخاضع للإشراف لدينا على مهمة التصنيف.
لنفترض أننا نريد تدريب نموذج التعلم الآلي على تصنيف الأرقام المكتوبة بخط اليد، ولكن كل ما لدينا هو مجموعة بيانات كبيرة من الصور غير المسماة للأرقام. إن وضع تعليقات توضيحية على كل مثال أمر غير وارد ونريد استخدام التعلم شبه الخاضع للإشراف لإنشاء نموذج الذكاء الاصطناعي الخاص بك.
أولاً، نستخدم تجميع الوسائل k لتجميع عيناتنا. K-mean هي خوارزمية تعلم سريعة وفعالة غير خاضعة للإشراف، مما يعني أنها لا تتطلب أي تسميات. K- يعني حساب التشابه بين عيناتنا عن طريق قياس المسافة بين ميزاتها. في حالة الأرقام المكتوبة بخط اليد، سيتم اعتبار كل بكسل ميزة، لذلك ستتكون الصورة 20 × 20 بكسل من 400 ميزة.
لنفترض أننا نريد تدريب نموذج التعلم الآلي على تصنيف الأرقام المكتوبة بخط اليد، ولكن كل ما لدينا هو مجموعة بيانات كبيرة من الصور غير المسماة للأرقام. إن وضع تعليقات توضيحية على كل مثال أمر غير وارد ونريد استخدام التعلم شبه الخاضع للإشراف لإنشاء نموذج الذكاء الاصطناعي الخاص بك.
أولاً، نستخدم تجميع الوسائل k لتجميع عيناتنا. K-mean هي خوارزمية تعلم سريعة وفعالة غير خاضعة للإشراف، مما يعني أنها لا تتطلب أي تسميات. K- يعني حساب التشابه بين عيناتنا عن طريق قياس المسافة بين ميزاتها. في حالة الأرقام المكتوبة بخط اليد، سيتم اعتبار كل بكسل ميزة، لذلك ستتكون الصورة 20 × 20 بكسل من 400 ميزة.

عند تدريب نموذج k-mean، يجب عليك تحديد عدد المجموعات التي تريد تقسيم بياناتك إليها. بطبيعة الحال، نظرًا لأننا نتعامل مع الأرقام، فقد يكون الدافع الأول لدينا هو اختيار عشر مجموعات لنموذجنا. لكن ضع في اعتبارك أن بعض الأرقام يمكن رسمها بطرق مختلفة. على سبيل المثال، إليك طرق مختلفة يمكنك من خلالها رسم الأرقام 4 و 7 و 2. يمكنك أيضًا التفكير في طرق مختلفة لرسم 1 و 3 و 9.

لذلك، بشكل عام، يجب أن يكون عدد المجموعات التي تختارها لنموذج التعلم الآلي للوسائل k أكبر من عدد الفصول الدراسية. في حالتنا، سنختار 50 مجموعة ، والتي يجب أن تكون كافية لتغطية الطرق المختلفة لرسم الأرقام.
بعد تدريب نموذج k-mean، سيتم تقسيم بياناتنا إلى 50 مجموعة. تحتوي كل مجموعة في نموذج k-mean a centroid، وهي مجموعة من القيم التي تمثل متوسط جميع الميزات في تلك المجموعة. نختار الصورة الأكثر تمثيلا في كل مجموعة، والتي تصادف أنها الصورة الأقرب إلى النقطه الوسطى. هذا يترك لنا 50 صورة من الأرقام المكتوبة بخط اليد.
بعد تدريب نموذج k-mean، سيتم تقسيم بياناتنا إلى 50 مجموعة. تحتوي كل مجموعة في نموذج k-mean a centroid، وهي مجموعة من القيم التي تمثل متوسط جميع الميزات في تلك المجموعة. نختار الصورة الأكثر تمثيلا في كل مجموعة، والتي تصادف أنها الصورة الأقرب إلى النقطه الوسطى. هذا يترك لنا 50 صورة من الأرقام المكتوبة بخط اليد.

الآن، يمكننا تسمية هذه الصور الخمسين واستخدامها لتدريب نموذج التعلم الآلي الثاني لدينا، المصنف، والذي يمكن أن يكون نموذج انحدار لوجستي، أو شبكة عصبية اصطناعية، أو آلة ناقلات دعم، أو شجرة قرار، أو أي نوع آخر من الخاضعين للإشراف محرك التعلم.
قد يبدو تدريب نموذج التعلم الآلي على 50 مثالًا بدلاً من آلاف الصور فكرة رهيبة. ولكن نظرًا لأن نموذج k-mean اختار 50 صورة كانت الأكثر تمثيلاً لتوزيعات مجموعة بيانات التدريب الخاصة بنا، فإن نتيجة نموذج التعلم الآلي ستكون رائعة. في الواقع، يُظهر المثال أعلاه، الذي تم اقتباسه من الكتاب الممتاز "التعلم الآلي العملي" باستخدام Scikit-Learn و Keras و Tensorflow، أن تدريب نموذج الانحدار على 50 عينة فقط تم اختيارها بواسطة خوارزمية التجميع ينتج عنه 92 بالمائة الدقة. في المقابل، يؤدي تدريب النموذج على 50 عينة تم اختيارها عشوائيًا إلى دقة 80-85 بالمائة.
ولكن لا يزال بإمكاننا الاستفادة بشكل أكبر من نظام التعلم شبه الخاضع للإشراف لدينا. بعد تسمية العينات التمثيلية لكل مجموعة، يمكننا نشر نفس الملصق على عينات أخرى في نفس المجموعة. باستخدام هذه الطريقة، يمكننا إضافة تعليقات توضيحية إلى آلاف الأمثلة التدريبية ببضعة أسطر من التعليمات البرمجية. سيؤدي ذلك إلى تحسين أداء نموذج التعلم الآلي الخاص بنا.
ولكن لا يزال بإمكاننا الاستفادة بشكل أكبر من نظام التعلم شبه الخاضع للإشراف لدينا. بعد تسمية العينات التمثيلية لكل مجموعة، يمكننا نشر نفس الملصق على عينات أخرى في نفس المجموعة. باستخدام هذه الطريقة، يمكننا إضافة تعليقات توضيحية إلى آلاف الأمثلة التدريبية ببضعة أسطر من التعليمات البرمجية. سيؤدي ذلك إلى تحسين أداء نموذج التعلم الآلي الخاص بنا.
تقنيات التعلم الآلي الأخرى شبه الخاضعة للإشراف
هناك طرق أخرى للقيام بالتعلم شبه الخاضع للإشراف، بما في ذلك آلات ناقلات الدعم شبه الخاضعة للإشراف (S3VM)، وهي تقنية تم تقديمها في مؤتمر NIPS لعام 1998. S3VM هي تقنية معقدة وتتجاوز نطاق هذه المقالة. لكن الفكرة العامة بسيطة ولا تختلف كثيرًا عما رأيناه للتو: لديك مجموعة بيانات تدريبية تتكون من عينات مصنفة وغير مسماة. يستخدم S3VM المعلومات من مجموعة البيانات المصنفة لحساب فئة البيانات غير المسماة، ثم يستخدم هذه المعلومات الجديدة لتحسين مجموعة بيانات التدريب.

إذا كنت مهتمًا بآلات متجه الدعم شبه الخاضعة للإشراف ، فراجع الورقة الأصلية واقرأ الفصل السابع من خوارزميات التعلم الآلي ، الذي يستكشف الأشكال المختلفة لآلات متجه الدعم (يمكن العثور على تطبيق S3VM في Python هنا).
تتمثل الطريقة البديلة في تدريب نموذج التعلم الآلي على الجزء المسمى من مجموعة البيانات الخاصة بك، ثم استخدام نفس النموذج لإنشاء تسميات للجزء غير المسماة من مجموعة البيانات الخاصة بك. يمكنك بعد ذلك استخدام مجموعة البيانات الكاملة لتدريب نموذج جديد.
حدود التعلم الآلي شبه الخاضع للإشراف
لا ينطبق التعلم شبه الخاضع للإشراف على جميع مهام التعلم تحت الإشراف. كما في حالة الأرقام المكتوبة بخط اليد، يجب أن تكون فصولك قابلة للفصل من خلال تقنيات التجميع. بدلاً من ذلك، كما هو الحال في S3VM ، يجب أن يكون لديك عدد كافٍ من الأمثلة المصنفة، ويجب أن تغطي هذه الأمثلة تمثيلًا عادلًا يمثل عملية توليد البيانات لمساحة المشكلة.
ولكن عندما تكون المشكلة معقدة ولا تمثل بياناتك المصنفة التوزيع بأكمله، فلن يساعد التعلم شبه الخاضع للإشراف. على سبيل المثال، إذا كنت ترغب في تصنيف الصور الملونة للكائنات التي تبدو مختلفة من زوايا مختلفة، فقد يساعدك التعلم شبه الخاضع للإشراف كثيرًا ما لم يكن لديك قدر كبير من البيانات المصنفة (ولكن إذا كان لديك بالفعل حجم كبير من البيانات المصنفة، إذن لماذا استخدام التعلم شبه تحت الإشراف؟). لسوء الحظ، تندرج العديد من تطبيقات العالم الحقيقي في الفئة الأخيرة، وهذا هو السبب في أن وظائف تصنيف البيانات لن تختفي في أي وقت قريبًا.
لكن لا يزال للتعلم شبه الخاضع للإشراف الكثير من الاستخدامات في مجالات مثل تصنيف الصور البسيط ومهام تصنيف المستندات حيث يمكن أتمتة عملية وسم البيانات.
التعلم شبه الخاضع للإشراف هو أسلوب رائع يمكن أن يكون مفيدًا إذا كنت تعرف متى تستخدمه.
تتمثل الطريقة البديلة في تدريب نموذج التعلم الآلي على الجزء المسمى من مجموعة البيانات الخاصة بك، ثم استخدام نفس النموذج لإنشاء تسميات للجزء غير المسماة من مجموعة البيانات الخاصة بك. يمكنك بعد ذلك استخدام مجموعة البيانات الكاملة لتدريب نموذج جديد.
حدود التعلم الآلي شبه الخاضع للإشراف
لا ينطبق التعلم شبه الخاضع للإشراف على جميع مهام التعلم تحت الإشراف. كما في حالة الأرقام المكتوبة بخط اليد، يجب أن تكون فصولك قابلة للفصل من خلال تقنيات التجميع. بدلاً من ذلك، كما هو الحال في S3VM ، يجب أن يكون لديك عدد كافٍ من الأمثلة المصنفة، ويجب أن تغطي هذه الأمثلة تمثيلًا عادلًا يمثل عملية توليد البيانات لمساحة المشكلة.
ولكن عندما تكون المشكلة معقدة ولا تمثل بياناتك المصنفة التوزيع بأكمله، فلن يساعد التعلم شبه الخاضع للإشراف. على سبيل المثال، إذا كنت ترغب في تصنيف الصور الملونة للكائنات التي تبدو مختلفة من زوايا مختلفة، فقد يساعدك التعلم شبه الخاضع للإشراف كثيرًا ما لم يكن لديك قدر كبير من البيانات المصنفة (ولكن إذا كان لديك بالفعل حجم كبير من البيانات المصنفة، إذن لماذا استخدام التعلم شبه تحت الإشراف؟). لسوء الحظ، تندرج العديد من تطبيقات العالم الحقيقي في الفئة الأخيرة، وهذا هو السبب في أن وظائف تصنيف البيانات لن تختفي في أي وقت قريبًا.
لكن لا يزال للتعلم شبه الخاضع للإشراف الكثير من الاستخدامات في مجالات مثل تصنيف الصور البسيط ومهام تصنيف المستندات حيث يمكن أتمتة عملية وسم البيانات.
التعلم شبه الخاضع للإشراف هو أسلوب رائع يمكن أن يكون مفيدًا إذا كنت تعرف متى تستخدمه.




